10 Best Deep Learning Courses to Take in 2024
Deep learning is all the rage these days. So I’ve compiled the best deep learning courses available online.

Deep learning is a machine learning technique that uses artificial neural networks to learn from data. And it’s all the rage these days!
In this guide, I’ve picked the best Deep Learning course from Class Central’s catalog of over 100K courses to find the best deep learning courses available.
You can read all about my ranking methodology below. But if you’re in a hurry, here are my top picks — click on a course to skip to the details:
| Course | Workload | In Brief |
| 1. Neural Networks and Deep Learning (DeepLearning.AI) | 27 hours | Best overall Deep Learning course for beginners |
| 2. Introduction to Deep Learning (MIT) | 20–50 hours | Rigorous and exciting Deep Learning course |
| 3. DS-GA 1008: Deep Learning (NYU) | 45 hours | Challenging Deep Learning course but very comprehensive |
| 4. Intro to Deep Learning with PyTorch (Facebook) | 8 weeks | Amazing deep learning intro with PyTorch |
| 5. Practical Deep Learning For Coders (fast.ai) | 70 hours | Comprehensive Deep Learning course with an emphasis on NLP |
| 6. Introduction to Deep Learning & Neural Networks with Keras (IBM) | 15 hours | Deep Learning course that teaches you just enough to get started |
| 7. Deep Learning with PyTorch: Zero to GANs (Jovian) | 12 hours | Deep learning basics — with free certificate |
| 8. Probabilistic Deep Learning with TensorFlow 2 (Imperial) | 53 hours | Intermediate level Deep Learning course with a focus on probabilistic models |
| 9. Machine Learning with Python: from Linear Models to Deep Learning (MIT) | 150–210 hours | Most comprehensive course for Machine Learning and Deep Learning |
| 10. Deep Learning Applications for Computer Vision (CU Boulder) | 25–40 hours | Deep Learning course with emphasis on computer vision |
What is Deep Learning?
To explain what deep learning is, let me first explain what machine learning is.
Machine learning involves enabling computers to learn from data largely on their own. For instance, you may implement a machine learning algorithm that can distinguish pictures of dogs from pictures of cats. Initially, the algorithm may not be very good at it. But as you train the algorithm by giving it examples of cats and dogs, it will learn to distinguish them.
Since the ability to ‘learn’ is considered a sign of intelligence, machine learning is hence a part of artificial intelligence. And deep learning is a subset of machine learning. It has the same goal as machine learning (to make computers learn) but approaches the problem with neural networks. Now, what are neural networks?
To put it simply, neural networks are made of neurons — but not neurons in the biological sense; we’re talking about software neurons. We call them like that because they behave similarly to neurons in our brains — that is, they can receive, process, and pass information.
Neural networks aim to replicate through artificial intelligence this biological mechanism that allows the powerful mushy computer in our heads to see, speak, hear, and react. As it turns out, programming a computer to simulate some brain mechanism works! Deep learning is what powers translation software, virtual assistants, deepfakes, self-driving cars, and a whole lot more.
You can see why companies are scrambling to find and incorporate AI and deep learning solutions into their products. In fact, the global deep learning market is expected to reach $93 billion by 2028. And artificial intelligence is mentioned dozens of times in the WEF’s Future of Jobs Report, denoting its importance in the job of tomorrow.

Course Ranking Methodology
I built this ranking following the now tried-and-tested methodology used in our previous rankings (you can find them all here). It involves a three-step process:
First, let me introduce myself. I’m a content writer for Class Central.
I (@elham), in collaboration with my friend and colleague @manoel, began by leveraging Class Central’s database of over 100K courses to make a preliminary selection of deep learning courses. We looked at indicators like ratings, reviews, and course bookmarks to bubble up some of the most loved and popular deep learning courses.
But we didn’t stop there. Ratings and reviews rarely tell the whole story. So the next step was to bring our personal knowledge of online education into the fold.
Second, we used our experience as online learners to evaluate each preliminary pick.
Both of us come from computer science backgrounds and are prolific online learners, having completed about 45 MOOCs between us. Additionally, Manoel has an online bachelor’s in computer science, while I am currently completing my foundation in computer science. Hence, deep learning is something both of us have struggled with!
By carefully analyzing each course and bouncing ideas off each other, we made iterative improvements to the ranking until we were both satisfied.
Third, during our research, we came across courses that we felt were well-made but weren’t well-known. Had we adopted a purely data-centric approach, we would be forced to leave those courses out of the ranking just because they had fewer enrollments.
So instead, we decided to take a more holistic approach. By including a wide variety of courses on deep learning, we hope this ranking will have something for everyone.
After going through this process — combining Class Central data, our experience as lifelong learners, and a lot of editing — we arrived at our final ranking. So far, we’ve spent more than 10 hours building this ranking, and we intend to continue updating it in the future.
Course Ranking Statistics
Here are some aggregate stats about the ranking:
- The most popular course in this ranking has over 1M enrollments.
- Combined, the enrollments add up to a total of 1.3M enrollments.
- All the courses are free or free-to-audit.
- Together, they account for over 10K bookmarks on Class Central.
- The most represented course provider on this list is Coursera.
- Around 171K people are following Deep Learning Courses on Class Central.
Now, let’s get to the top picks!
1. Neural Networks and Deep Learning (DeepLearning.AI)

My #1 pick for the best deep learning course is Neural Networks and Deep Learning from DeepLearning.AI on Coursera. If you want to break into cutting-edge AI, this course will help you do so.
The reason why this course is ranked this highly is because it’s a great option to gain a fundamental understanding of deep learning and it is taught by none other than Andrew Ng — a prominent figure in the world of machine learning. The course teaches you how deep learning actually works, rather than presenting only a surface-level description.
By the end of this course you’ll understand the major technology trends driving deep learning, you’ll be able to build, train and apply fully connected deep neural networks, you’ll know how to implement efficient (vectorized) neural networks, you’ll understand the key parameters in a neural network’s architecture, and the most exciting of all, you’ll build a deep neural network that can recognize cats!
This course is for motivated students with some understanding of classical machine learning and for early-career software engineers or technical professionals looking to master the fundamentals and gain practical machine learning and deep learning skills.
What You’ll Learn
The course starts with an introduction to deep learning that favors learning through examples. You’ll learn what supervised learning is and how it relates to deep learning before exploring the three major trends driving the rise of deep learning: data, computation, and algorithms. You’ll list the major categories of models — such as convolutional and recurrent neural networks — and you’ll discuss appropriate use cases for each.
In the second week, you’ll learn about the basics of neural network Python programming using the popular library NumPy. You’ll code in Jupyter Notebooks. You’ll tackle a machine learning problem using a neural network and use vectorization to speed up your models. Along the way, you’ll learn several key concepts, like backpropagation, cost function, and gradient descent.
Having learned the framework for neural network programming, the third week is all about building single hidden layer neural networks, also known as shallow neural networks.
Finally in the fourth and final week, you will build a 2-layer neural network, also known as a deep neural network. You’ll analyze the key computations underlying deep learning, then use them to build and train deep neural networks for computer vision tasks — in this case, identifying pictures of cats!
How You’ll Learn
This course is 4 weeks long, with 27 hours worth of material. If you pay for a certificate, at the end of each week, there are also 10 multiple-choice questions that you can use to double check your understanding of the material, and upon course completion, you’ll earn a certificate.
| Institution | DeepLearning.AI |
| Provider | Coursera |
| Instructor | Andrew Ng |
| Level | Intermediate |
| Workload | 27 hours total |
| Enrollments | 1M |
| Rating | 4.9 / 5.0 (113K) |
| Certificate | Paid |
Fun Facts
- The course has 13.6K bookmarks on Class Central.
- Neural Networks and Deep Learning is the first course of the Deep Learning Specialization. The specialization will help you understand the capabilities, challenges, and consequences of deep learning and prepare you to participate in the development of leading-edge AI technology.
- The second course in this series is Improving Deep Neural Networks: Hyperparameter Tuning, Regularization and Optimization.
- Andrew Ng is the co-founder and head of Google Brain and was the former chief scientist at Baidu.
- He also co-founded Coursera, before creating DeepLearning.AI.
If you’re interested in this course, you can find more information about the course and how to enroll here.
2. 6.S191: Introduction to Deep Learning (Massachusetts Institute of Technology)
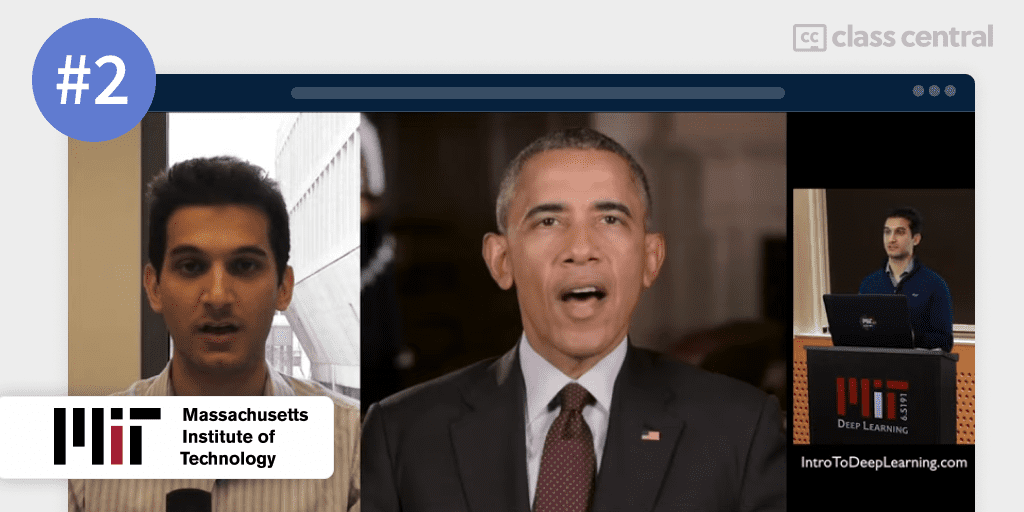
My second pick for the best deep learning course is MIT’s 6.S191: Introduction to Deep Learning.
Running yearly since 2017 and open to all for registration, MIT’s introductory course will teach you the foundational knowledge of deep learning as well as help you gain practical experience in building neural networks in TensorFlow. You’ll learn how deep learning methods relate to applications like computer vision, natural language processing, biology, and more!
As the course syllabus changes year-to-year, I will write about the last completed session: the 2021 course content. You can find the 2022 content on their course website.
The course assumes elementary knowledge of linear algebra and calculus (e.g: matrix multiplication and derivatives). Experience in Python is also helpful but not necessary. If you want to learn or brush up on Python, check out my Python Courses ranking.
What You’ll Learn
The course begins with… a welcome speech by Obama?!? Oh wait, it’s actually Alexander Amini, the course instructor, somehow portraying himself as Obama! What a wonderful introduction to the field of deep learning!
You’ll learn about several foundational concepts in deep learning, like how neural networks are just perceptrons (little computational gates that can let a signal through depending on conditions that can change over time) stacked on top of one another, optimized through backpropagation. You’ll also learn how neural networks are trained by feeding them data, and the precautions we should take when training them.
The next module is on sequence modeling. From predicting the direction of moving objects to heartbeats to global temperature to natural language, sequences are everywhere. Recurrent neural networks are suited to deal with sequence modeling tasks.
Making computers see has always been an exciting idea. Unfortunately, computers see images as collections of zeroes and ones. How can we help computers find complex features in images then? Convolutional neural networks do the trick! You’ll learn how models can learn to recognize features in images.
So how did Alexander Amini manage to generate a realistic deepfake of himself as Obama? You’ll find the answer in this section on generative modeling. Unlike the previous models where you apply labels to data (for instance, you tell the model that the image represents a cat), in generative modeling there is no label to begin with! This is called unsupervised learning, and its goal is to learn the hidden structure beneath data. You’ll study two kinds of unsupervised models: Variational Autoencoders (VAE) and Generative Adversarial Networks (GANS).
So you’ve learned about supervised and unsupervised learning. Time to introduce you to a new category: reinforcement learning. And this is one of the great things about this course: it covers a lot of ground — not all deep learning courses touch on reinforcement learning.
Reinforcement learning is the type of learning that enables AI to play Mario or robots to walk. In reinforcement learning you have an agent placed in an environment with a desired goal to be achieved. Your agent then gets rewarded for certain tasks (the ones you want the agent to accomplish) and penalized for others. For there, the agent must iteratively learn a policy that maximizes rewards. That’s reinforcement learning in a nutshell.
The course explores a few interesting prospects, like representing data with graph neural networks and automated machine learning, but there are limitations. For example, it is difficult for an AI to tell how confident it is in its predictions, and AI is also susceptible to bias, be it malicious or accidental. Fortunately, work is being done to hopefully prevent AI from doing more harm than good, and you’ll learn how you can be a part of this.
The final few lectures in the course are taught by guest lecturers from respected institutions like Google and Nvidia. You’ll be taught about learning for information extraction, taming dataset bias, AI for 3D content creation, and AI in healthcare.
How You’ll Learn
This course is 9 weeks long, with a total of 12 lecture videos that add up to about 10 hours of watch time. The lecture videos are well-produced and clear, and the supplementary resources are also handy.
Regarding assessments, there are plenty of software labs run in Google Colab. You’ll learn by doing — following along the instructor, writing code, and running it to see the magical results of deep learning.
| Institution | Massachusetts Institute of Technology |
| Provider | MITOpenCourseWare |
| Instructors | Alexander Amini and Ava Soleimany |
| Level | Beginner |
| Workload | 20–50 hours total |
| Views | 1.7M |
Fun Facts
- The course has 782 bookmarks on Class Central.
- The course’s high production values are reminiscent of Harvard’s CS50 or MIT’s self-driving cars course. There’s a huge team behind the course!
If you’re interested in this course, you can find more information about the course and how to enroll here.
3. DS-GA 1008: Deep Learning (New York University)

DS-GA 1008: Deep Learning discusses the latest techniques in deep learning and representation learning, focusing on supervised and unsupervised deep learning, embedding methods, metric learning, convolutional and recurrent nets, with applications to computer vision, natural language understanding, and speech recognition.
The course is taught by none other than Yann LeCun, a prominent figure in machine learning, and considered the father of convolutional neural networks. You’re learning from the very best here. Here’s the course website.
The prerequisite for this course is taking DS-GA 1001 Intro to Data Science or a graduate-level machine learning course.
What You’ll Learn
The course consists of 8 themes: Introduction; Parameters Sharing; Energy Based Models, Foundations; Energy Based Models, Advanced; Associative Memories; Graphs; Control; and Optimisation.
You’ll start by delving into the history of machine learning and deep learning, and their differences. Then, you’ll discuss the motivations behind neural networks, and study the mathematical principles underlying them, including chain rule derivation, backpropagation, and gradient descent.
There are many different types of neural networks. The ones you’ll learn about are recurrent and convolutional neural networks, and you’ll explore how these neural networks are used in digit recognition and other applications.
Next, you’ll be introduced to a new framework for defining supervised, unsupervised, and self-supervised models — the Energy-Based Model approach. Through this lens, the course will explore autoencoders, generative models like generative adversarial networks (GANs), transformers, and a lot more.
The course discusses the problem of speech recognition using neural models, specifically graph transformer networks. Yes, now is the time for graph theory! You’ll learn about beam search and other algorithms to help you tackle this problem.
You’ll then study planning and control, and lastly, about optimization — a crucial topic in machine learning. Most notably, this lesson will touch on stochastic gradient descent.
How You’ll Learn
This course is 15 weeks long, with each week having around 3 hours of video lectures. This course is brimming with resources — video lectures, GitHub notes, Jupyter notebooks, the works!
Regarding assignments, you’ll complete a variety of labs and homework to strengthen your knowledge of machine learning and deep learning through hands-on coding.
| Institution | New York University |
| Provider | YouTube |
| Instructors | Yann LeCun and Alfredo Canziani |
| Level | Intermediate |
| Workload | 45 hours total |
| Views | 81K |
| Certificate | None |
Fun Facts
- You can find the course notes here: DEEP LEARNING · Deep Learning (atcold.github.io)
- I have to say it again: you’re learning from the best here. Yann LeCun’s reputation in the world of machine learning and deep learning can’t be overstated.
If you’re interested in this course, you can find more information about the course and how to enroll here.
4. Intro to Deep Learning with PyTorch (Facebook)

Deep learning is driving the AI revolution and PyTorch is making it easier than ever for anyone to build deep learning applications.
Offered by Facebook on Udacity, Intro to Deep Learning with PyTorch aims to teach you the basics of deep learning, and build your own deep neural networks using PyTorch.
You’ll gain practical experience building and training deep neural networks through coding exercises and projects. And you’ll implement state-of-the-art AI applications using style transfer and text generation.
To succeed in this course, you’ll need to be comfortable with Python and data processing libraries such as NumPy and Matplotlib. Basic knowledge of linear algebra and calculus is recommended, but isn’t required to complete the exercises.
What You’ll Learn
The course begins with an introduction to deep learning with PyTorch. You’ll discover the basic concepts of deep learning, such as neural networks and gradient descent. Then, you’ll use NumPy to apply these concepts to create a neural network that predicts student admissions.
Now that you have programmed a neural network with NumPy, you’ll see how pleasant it is to instead program with PyTorch! After an interview with Soumith Chintala, the creator of PyTorch, you’ll focus on computer vision — making computers understand images and videos. You’ll learn about convolutional neural networks (CNN) that will allow you to classify images of cats, clothes, and dog breeds.
Time to get artistic! You’ll gain some understanding of the theory used in the influential paper A Neural Algorithm of Artistic Style, and use a pre-trained CNN to create art by merging the style of one image with the content of another image. This is called neural style transfer, and it’s quite impressive: you can make any picture look like a painting, for instance.
Next, you’ll see how recurrent neural networks (RNN) can be used to imitate sequential data like text. Moving into the field of neural language processing, you’ll implement RNN to generate realistic text based on Tolstoy’s Anna Karenina. You’ll also learn about sentiment prediction — determining whether a given text is positive, negative or neutral. You’ll build another RNN to predict the sentiment of movie reviews.
Lastly, you’ll learn how to deploy deep learning models with PyTorch. PyTorch allows you to export your models from Python into C++. You’ll create a chatbot and compile its neural network for deployment in a production environment
How You’ll Learn
This course is 8 weeks long. The videos and lectures are wonderfully produced and presented in an interesting and engaging format.
You’ll apply what you’ve been taught by coding in the various Jupyter notebooks provided. The exercises are easy to follow with walkthrough solutions.
| Institution | |
| Provider | Udacity |
| Instructors | Luis Serrano, Alexis Cook, Soumith Chintala, Cezanne Camacho and Mat Leonard |
| Level | Intermediate |
| Workload | 8 weeks total |
Fun Facts
- The course has 357 bookmarks and 4.5 ratings from 2 reviews on Class Central.
- Luis Serrano, the lead instructor, has worked at Google and Apple, and he’s now a research scientist in quantum AI. He has quite the resume! And according to my colleague @manoel who has taken one of his courses, he’s a fantastic instructor.
If you’re interested in this course, you can find more information about the course and how to enroll here.
5. Practical Deep Learning For Coders (Fast.AI)
Practical Deep Learning For Coders by fast.ai starts from step one— learning how to get a GPU server online suitable for deep learning — and goes all the way through to creating state-of-the-art models for computer vision, natural language processing, recommendation systems, and more!
In this course you’ll also learn how to use the libraries PyTorch and fastai. PyTorch works best as a low-level library, while fastai adds a higher-level functionality on top of PyTorch.
One cool thing about this course is that it teaches you how to set up a cloud GPU to train models on, as well as how to use Jupyter Notebooks to write and experiment with code.
This course is designed for anyone with at least a year of coding experience (preferably in Python) and some memory of high-school math.
What You’ll Learn
Starting with the first lesson, you’ll learn what deep learning is and how it’s related to machine learning and regular computer programming. You’ll look at critical machine learning topics and learn how to create production-ready models. This includes learning about confidence intervals and discussing the overall project plan for model development.
Time to create and deploy your own app! But before that, you’ll discuss data augmentation and learn the underlying math and code of stochastic gradient descent. You’ll build a GUI for your app, both for interactive apps inside notebooks and standalone web applications. You’ll then learn how to deploy web applications that incorporate deep learning models.
Next, you’ll dive deep into the foundations of neural net functioning, by training a network from scratch. You’ll learn about the sigmoid function, and see why it’s needed for classification models, along with a couple of handy features associated with arrays and tensors in Python. Then, you’ll study how gradients are calculated and used in a PyTorch training loop. We go from a simple single-layer network, to create our first ‘deep’ network from scratch!
Sometimes, machine learning models can go wrong. It is likely that at some point, you’ll be put in a situation where you need to consider data ethics — using data for good. The course discusses some useful ways to think about data ethics, particularly through the lens of a number of case studies.
Going back to deep learning, you’ll dive deeper into the softmax activation function, used in most non-binary classification models. You’ll then learn about multi-label problems — why they can be useful even in situations where you expect each object to fall into just one category.
Decision trees and ensembles of decision trees (random forests and gradient boosting machines) are often used for tabular data, and are much easier to explain and understand. But there are also some limitations of decision tree approaches, particularly in extrapolation, and you’ll look at ways around this problem. Using these approaches, you’ll arrive at a Kaggle solution close to the top of the leaderboard in a popular competition!
The final lesson of this course is all about natural language processing (NLP). Modern NLP depends heavily on self-supervised learning, and in particular the use of language models.
You’ll learn how to tokenize and numericalize text data, as well as an approach called word embedding. You’ll also be introduced to a new architecture known as recurrent neural networks. Lastly, you’ll look at some tricks to improve the results of our NLP models.
How You’ll Learn
There are around 20 hours of lessons, and you should plan to spend around 10 hours a week on the course for 7 weeks to complete the material.
| Institution | fast.ai |
| Instructor | Jeremy Howard |
| Level | Intermediate |
| Workload | 70 hours total |
| Certificate | None |
Fun Facts
- The course has 28.8K bookmarks and 8 reviews on Class Central.
- Deep Learning for Coders with Fastai and PyTorch: AI Applications Without a PhD is the accompanying book for this course. It is also freely available as a series of Jupyter Notebooks.
If you’re interested in this course, you can find more information about the course and how to enroll here.
6. Introduction to Deep Learning & Neural Networks with Keras (IBM)
Introduction to Deep Learning & Neural Networks with Keras by IBM introduces you to the field of deep learning. This course will not teach you everything about deep learning, but it will teach you just enough to get started on more advanced courses and learn independently.
You will learn about the different deep learning models and build your first deep learning model using the Keras library. By the end of this course, you’ll be able to describe neural networks and deep learning models, understand unsupervised deep learning models (autoencoders and restricted Boltzmann machines) and supervised deep learning models (convolutional neural networks and recurrent networks), and most importantly, build deep learning models and networks using the Keras library.
To take this course you should have some Python programming knowledge and a little experience with machine learning.
What You’ll Learn
You’ll begin by exploring the exciting applications of deep learning, like restoring color in black and white photos and synthesizing audio. You’ll learn about biological and artificial neural networks and how most of the deep learning algorithms are inspired by the way our brain processes data. Then, you’ll learn about forward propagation.
Next, you’ll learn about the gradient descent algorithm and how variables are optimized with respect to a defined function. You’ll learn about the brother of forward propagation, backpropagation, and how neural networks learn and update their weights and biases through this process. Finally, you’ll learn how activation functions work.
Now begins the more practical part of the course: Keras and deep learning libraries! You’ll discover the different deep learning libraries: Keras, PyTorch, and TensorFlow, but as the course name implies, you’ll focus on building models using Keras.
What’s the difference between shallow and deep neural networks? The next section of the course answers this question. Additionally, you’ll learn what convolutional networks are and how to build them with Keras. You’ll also learn about recurrent neural networks and autoencoders.
The final module is a course project. You’ll end the course by working on a final assignment where you’ll use the Keras library to build a regression model and experiment with the depth and the width of the model.
How You’ll Learn
This course is 5 weeks long, with each week taking 2–3 hours of study. Each week comes with a quiz to test your understanding, with the last week dedicated to building a final project and reviewing your peers’ work. The assessments can only be accessed if you are paying for the certificate.
| Institution | IBM |
| Provider | Coursera |
| Instructor | Alex Aklson |
| Level | Intermediate |
| Workload | 15 hours total |
| Enrollments | 24K |
| Rating | 4.7 / 5.0 (1K) |
| Certificate | Paid |
Fun Facts
- This course is part of the 6-course IBM AI Engineering Professional Certificate, which is designed to equip you with the tools you need to succeed in your career as an AI or ML engineer. The course prior to this is Machine Learning with Python.
- Introduction to Deep Learning & Neural Networks with Keras has 108 bookmarks on Class Central.
If you’re interested in this course, you can find more information about the course and how to enroll here.
7. Deep Learning with PyTorch: Zero to GANs (Jovian)

Deep Learning with PyTorch: Zero to GANs by Jovian provides a coding-first introduction to deep learning using the PyTorch framework.
The course is called “Zero to GANs” because it assumes no prior knowledge of deep learning (i.e. you can start from zero), and by the end of the six weeks, you’ll be familiar with building Generative Adversarial Networks or GANs.
Although this course is suitable for beginners, it is recommended to have some programming knowledge, preferably in Python, knowledge of the basics of linear algebra (vectors, matrices, dot products) as well as the basics of calculus (differentiation, geometric interpretation of derivative).
What You’ll Learn
The course begins by covering the basics of PyTorch: tensors, gradients, and autograd. These concepts will help you understand linear regression and gradient descent, which you’ll then implement from scratch using PyTorch.
Afterwards, you’ll further your knowledge of linear regression and gradient descent. You’ll work with the ‘Hello World!’ dataset of deep learning: MNIST — a dataset of handwritten digits. Here, your aim is to determine what number an image represents. To accomplish this, you’ll perform a training-validation split on the dataset, and learn about logistic regression. After that, you’ll train, evaluate and sample predictions from your model.
Now you’ll move on to much more complex topics. You’ll start by creating a deep neural network with hidden layers and non-linear activations. But training deep neural networks can be time-consuming, especially since you’ll want to tweak certain hyperparameters and retrain your model again. So, instead of using your own GPU, you’ll use cloud-based GPUs to handle all the computational work.
So previously you used a regular deep neural network to determine the numbers in your dataset and saw how well that worked. You’ll be surprised when you learn how convolutional neural networks are vastly superior at image classification! This will entail learning some key concepts though, like convolutions, residual connections, batch normalization and so on, as well as avoiding underfitting & overfitting.
Finally, you’ll get to the cream of the crop: Generative Adversarial Networks (GANs). GANs are different from the other models that you’ve learned in that they are creative. You’ll train generator and discriminator networks to build a few applications like generating fake digits and anime faces.
How You’ll Learn
The course is 6 weeks long with 12 hours worth of video lecture content. The course utilizes a hands-on approach by allowing you to follow along and experiment with code in Jupyter Notebooks.
Regarding assessments, you’ll receive weekly assignments and work on various projects with real-world datasets to hone your skills.
| Institution | Jovian |
| Instructor | Aakash N S |
| Level | Beginner |
| Workload | 12 hours total |
| Certificate | Free |
Fun Facts
- Jovian also offers many other Python courses related to Data Science, like Data Analysis with Python and Machine Learning with Python.
- This course includes a free certificate upon completion.
If you’re interested in this course, you can find more information about the course and how to enroll here.
8. Probabilistic Deep Learning with TensorFlow 2 (Imperial College London)

Offered by Imperial College London, Probabilistic Deep Learning with TensorFlow 2 builds on the foundational concepts of TensorFlow 2 and focuses on the probabilistic approach to deep learning — getting the model to know what it doesn’t know.
You will learn how to develop probabilistic models with TensorFlow, making particular use of the TensorFlow Probability library.
This course is a continuation of the previous two courses in the specialization, Getting started with TensorFlow 2 and Customising your models with TensorFlow 2. The additional prerequisite knowledge required in order to be successful in this course is a solid foundation in probability and statistics (e.g: standard probability distributions, probability density functions, maximum likelihood estimation).
What You’ll Learn
The first module is TensorFlow Distributions. Probabilistic modeling is a powerful and principled approach that takes account of uncertainty in the data. The TensorFlow Probability (TFP) library provides tools for developing probabilistic models that extend the capability of TensorFlow. You’ll learn how to use the Distribution objects in TFP, and the key methods to sample from and compute probabilities from these distributions and make these distributions trainable.
Accounting for sources of uncertainty is a crucial aspect of the modeling process, especially when people are at stake such as medical diagnoses. Unlike most standard deep learning models, probabilistic modeling does not fail to neglect this. In the second module you’ll learn how to use probabilistic layers from TensorFlow Probability to develop deep learning models that are able to provide measures of uncertainty in both the data, and the model itself.
Normalizing flows are a powerful class of generative models that models the underlying data distribution by transforming a simple base distribution through a series of bijective transformations. The third module teaches you how to use bijector objects from the TensorFlow Probability library to implement these transformations, and learn a complex transformed distribution from data. These models can be used to sample new data generations, as well as evaluate the likelihood of data examples.
In the fourth module, you’ll learn how to implement the variational autoencoders (VAE) using the TensorFlow Probability library. In a VAE algorithm two networks are jointly trained: an encoder or inference network, as well as a decoder or generative network. You’ll use the trained networks to encode data examples into a compressed latent space, as well as generate new samples from the prior distribution and the decoder.
The final module brings together many of these concepts you’ve studied in the last four modules by giving you a task: Create a synthetic image dataset using normalizing flows, and train a variational autoencoder on the dataset. After completing the capstone project, you can proudly say that you have learnt quite a lot about probabilistic deep learning models using tools and concepts from the TensorFlow Probability library.
How You’ll Learn
This course is 5 weeks long, with 53 hours worth of material. There are plenty of videos and readings available for you to follow along.
Assessments are only available for paying learners. In the assessments, you’ll apply the concepts that you learn about into practice through practical, hands-on coding tutorials. In addition, there is a series of automatically graded programming assignments for you to consolidate your skills.
| Institution | Imperial College London |
| Provider | Coursera |
| Instructor | Kevin Webster |
| Level | Advanced |
| Workload | 53 hours total |
| Enrollments | 9K |
| Rating | 4.7 / 5.0 (70) |
| Certificate | Paid |
Fun Facts
- This course is part of the TensorFlow 2 for Deep Learning Specialization.
If you’re interested in this course, you can find more information about the course and how to enroll here.
9. Machine Learning with Python: from Linear Models to Deep Learning (Massachusetts Institute of Technology)

Have you looked through all the previous courses and realized that you do not have a foundational grasp of machine learning, but do want to eventually learn about deep learning? If you’re up for the challenge (and are willing to stomach some mathematics), this rigorous MIT course is for you!
Machine Learning with Python: from Linear Models to Deep Learning introduces you to the field of machine learning, from linear models to deep learning and reinforcement learning, with a hands-on approach. You’ll implement and experiment with the algorithms in several Python projects designed for different practical applications.
To be successful in this course, you should be proficient in Python programming (6.00.1x), as well as probability theory (6.431x), college-level single and multivariable calculus, and vectors and matrices.
What You’ll Learn
The course begins with a brief review of linear algebra and probability, the foundational cornerstones of machine learning. Afterwards, you’ll get your first taste of machine learning and its principles, including training, validation, parameter tuning, and feature engineering.
After getting the principles down, you’ll begin with the most popular flavor of machine learning: supervised learning. You’ll learn about linear classifiers and encounter various problems in machine learning like hinge loss, margin boundaries, and regularization, as well as how to combat them. You’ll end your first unit by building an automatic review analyzer.
In the second unit, you’ll learn about nonlinear classification, linear regression, and collaborative filtering. This includes lessons on stochastic gradient descent, over-fitting, and generalization. With these concepts in mind, you’ll create the first part of a digit recognition model.
The third unit introduces you to deep learning and neural networks. You’ll learn how neural networks are constructed and the two common types of neural networks: recurrent neural networks and convolutional machine learning. Finally, you’ll complete your digit recognition model.
Unsupervised learning is the focus of the fourth unit of this course, where you’ll mainly learn about clustering and expectation–maximization (EM) algorithms, and generative and mixture models. The unit’s project consists of developing a collaborative filtering model via the EM algorithm.
The fifth and final unit is about reinforcement learning, which is where you reward or punish the machine based on whether it achieves a desired goal or not. You’ll also learn about natural language processing, where you’ll make a text-based game as your final project.
How You’ll Learn
This course is 15 weeks long, with an expected 10—14 hours spent studying each week. You’ll be provided with plenty of lectures and resources to study and learn from.
Regarding assessments, there are three projects which you’ll have to complete, along with a mid-year and final-year exam.
| Institution | Massachusetts Institute of Technology |
| Provider | edX |
| Instructors | Regina Barzilay, Tommi Jaakkola, and Karene Chu |
| Level | Advanced |
| Workload | 150–210 hours total |
| Enrollments | 154K |
| Certificate | Paid |
Fun Facts
- The course has 757 bookmarks on Class Central.
- This course is part of the Statistics and Data Science MicroMasters Program.
If you’re interested in this course, you can find more information about the course and how to enroll here.
10. Deep Learning Applications for Computer Vision (University of Colorado Boulder)

From the University of Colorado Boulder, Deep Learning Applications for Computer Vision will guide you through the field of Computer Vision from a hands-on approach.
In this course, you’ll be learning about Computer Vision as a field of study and research. By the end of the course, you’ll be equipped with both deep learning techniques and machine learning tools needed to fulfill any computer vision task.
The prerequisites for this course are basic calculus (differentiation and integration), linear algebra, and proficiency in Python programming.
What You’ll Learn
In the first module, you’ll learn about the field of Computer Vision. Computer Vision has the goal of extracting information from images — from object detection and recognition for face recognition, to motion tracking for autonomous driving cars. With the adoption of Machine Learning and Deep Learning techniques, you’ll take a look at how this has impacted the field of Computer Vision.
The second module introduces you to classic Computer Vision tools and techniques. You’ll describe the reasoning behind certain algorithmic steps and understand the convolution operation and how image filters are applied. More importantly, you’ll explain the steps and process behind classic algorithmic solutions to Computer Vision tasks and lay out the advantages and disadvantages.
Next, you’ll review the challenges for object recognition in Classic Computer Vision in the third module. Then, you’ll go through the steps of achieving object recognition and image classification in the Classic Computer Vision pipeline.
Neural Networks and Deep Learning make up the fourth module. You’ll compare how the image classification pipeline with neural networks differs from pipelines of classic computer vision tools. Then, you’ll review and identify the basic components of a neural network as well as the steps needed to train a network model. This module concludes with a tutorial in TensorFlow where you’ll have hands-on coding experience practicing how to build, train and use a neural network for image classification predictions.
Continuing what you’ve learned previously, the fifth and final module is about the Convolutional Neural Networks (CNN) — a major player in Computer Vision! You’ll study the structure and layers of CNNs, along with understanding how parameters and hyperparameters describe a deep network and how they can help improve the accuracy of the deep learning models. Finally, you’ll finish this course by building, training and using a deep neural network for image classification.
How You’ll Learn
The course is 5 weeks long, with each week taking 5—8 hours. You’ll learn from the various video lectures as well as the supplemental resources provided in the course.
Each week comes with a graded assessment that you’ll have to complete, along with a final quiz, if you are paying for certification.
| Institution | University of Colorado Boulder |
| Provider | Coursera |
| Instructor | Ioana Fleming |
| Level | Intermediate |
| Workload | 25–40 hours total |
| Certificate | Paid |
Fun Facts
- The Deep Learning Applications for Computer Vision course is actually a part of their Master of Science in Data Science degree, meaning you’ll learn what university students learn!
- It uses the book Computer Vision: A Modern Approach, which is helpful but not necessary.
If you’re interested in this course, you can find more information about the course and how to enroll here.






